
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- RequestMappingHandlerMapping
- wrapper class
- IllegalStateException
- demand paging
- Transaction
- #@Transacional
- cross-cutting concerns
- pessimistic lock
- propagation
- 단어변환
- generic type
- 역정규화
- COPYOFRANGE
- optimistic lock
- TDZ
- Java
- HandlerMethod
- assertJ
- CQS
- 벌크연산
- type eraser
- CORS
- NestJS 요청흐름
- API
- Generic method
- tracking-modes
- 프로그래머스
- hoisting
- ExceptionResolver
- SPOF
Archives
- Today
- Total
jingyulog
왜 DB Index로 B tree 계열이 사용되는가? 본문
B tree 계열에는 B+ tree, B* tree가 있는데, 시간복잡도를 계산했을때 average case와 worst case 모두 조회, 삽입, 삭제에서 O(logN)이 나온다. 그런데 self-balancing BST의 종류인 AVL tree와 Red-Black tree의 average case와 worst case 모두 조회, 삽입, 삭제에서 시간복잡도 O(logN)이 나온다. 그렇다면 이제 왜 DB index로 B tree 계열이 사용되는지 알아보자.
computer system
- CPU : 프로그램의 코드가 실제로 실행되는 곳
- Main memory(RAM) : 실행중인 프로그램의 코드들과 코드 실행에 필요한 혹은 그 결과로 나온 데이터들이 상주하는 곳
- Secondary Storage(SSS or HDD) : 프로그램과 데이터가 영구적으로 저장되는 곳, 실행중인 프로그램의 데이터 일부가 임시 저장되는 곳(SWAP)
secondary storage
- 데이터를 처리하는 속도가 가장 느리다.
- 데이터를 저장하는 용량이 가장 크다.
- block 단위로 데이터를 읽고 쓴다.
- 여기서 block이란 file system이 데이터를 읽고 쓰는 논리적인 단위를 말한다.
- block의 크기는 2의 승수로 표현되며, 대표적인 block size는 4KB, 8KB, 16KB 등이 있다.
- 불필요한 데이터까지 읽어올 가능성이 있다.
database
- DB는 secondary storage에 저장된다.
- DB에서 데이터를 조회할 때, secondary storage에 최대한 적게 접근하는 것이 성능 면에서 좋다.
- block 단위로 읽고 쓰기 때문에 연관된 데이터를 모아서 저장하면 더 효율적으로 읽고 쓸 수 있다.
CREATE INDEX(b)
다음 테이블의 b column을 대상으로 index를 만들어보자.

이때, AVL tree index(b) 와 B tree index(b)를 비교하는 상황이다.
- 가정 상황
- tree의 각 노드는 서로 다른 block에 있다.
- 초기에는 root 노드를 제외한 모든 노드는 secondary storage에 있다고 가정한다.
- 초기에는 데이터 자체도 모두 secondary storage에 있다고 가정한다.
- AVL tree의 경우 총 4번 secondary storage에 접근한다.
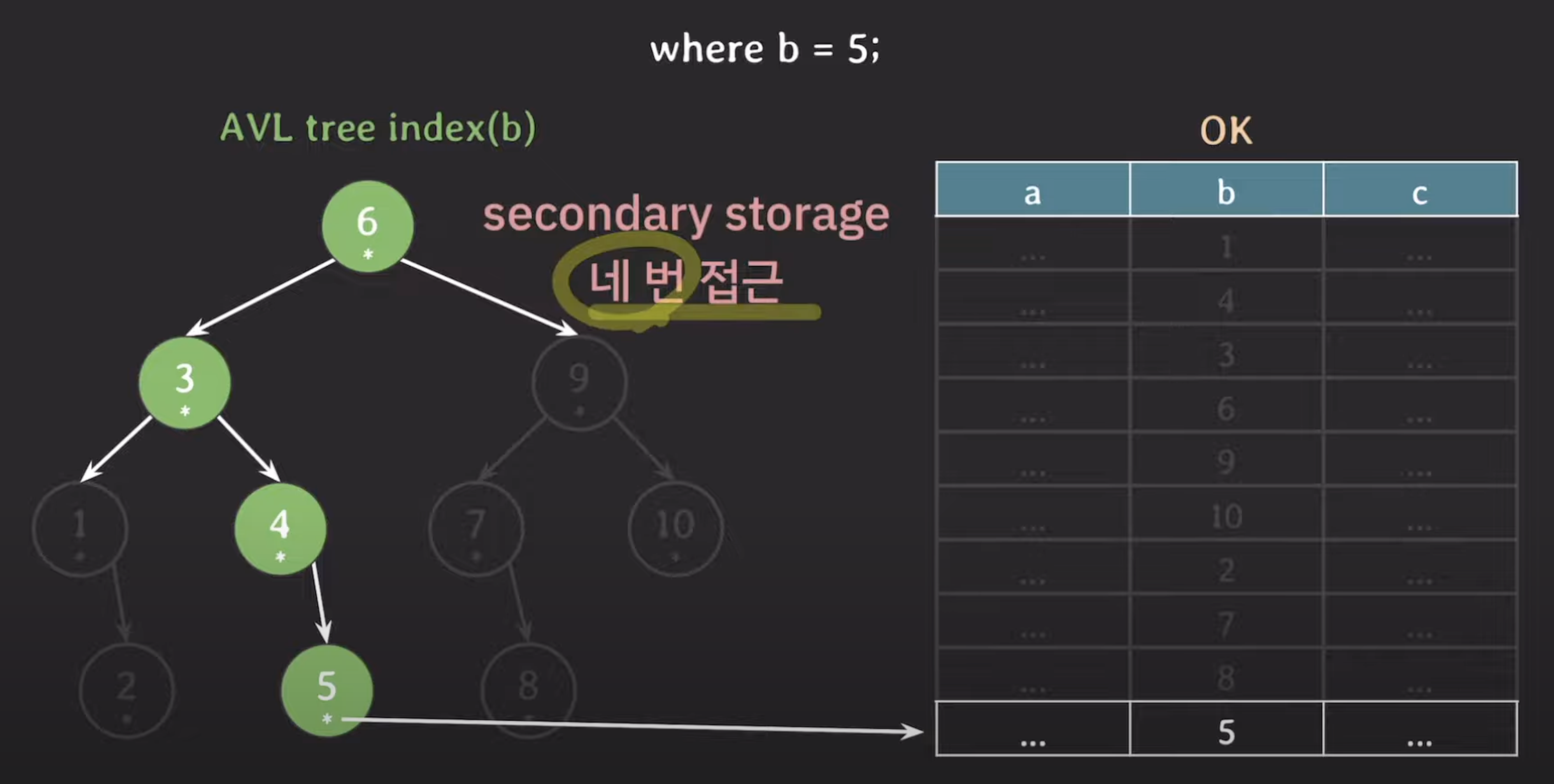
- B tree의 경우 총 2번 secondary storage에 접근한다.
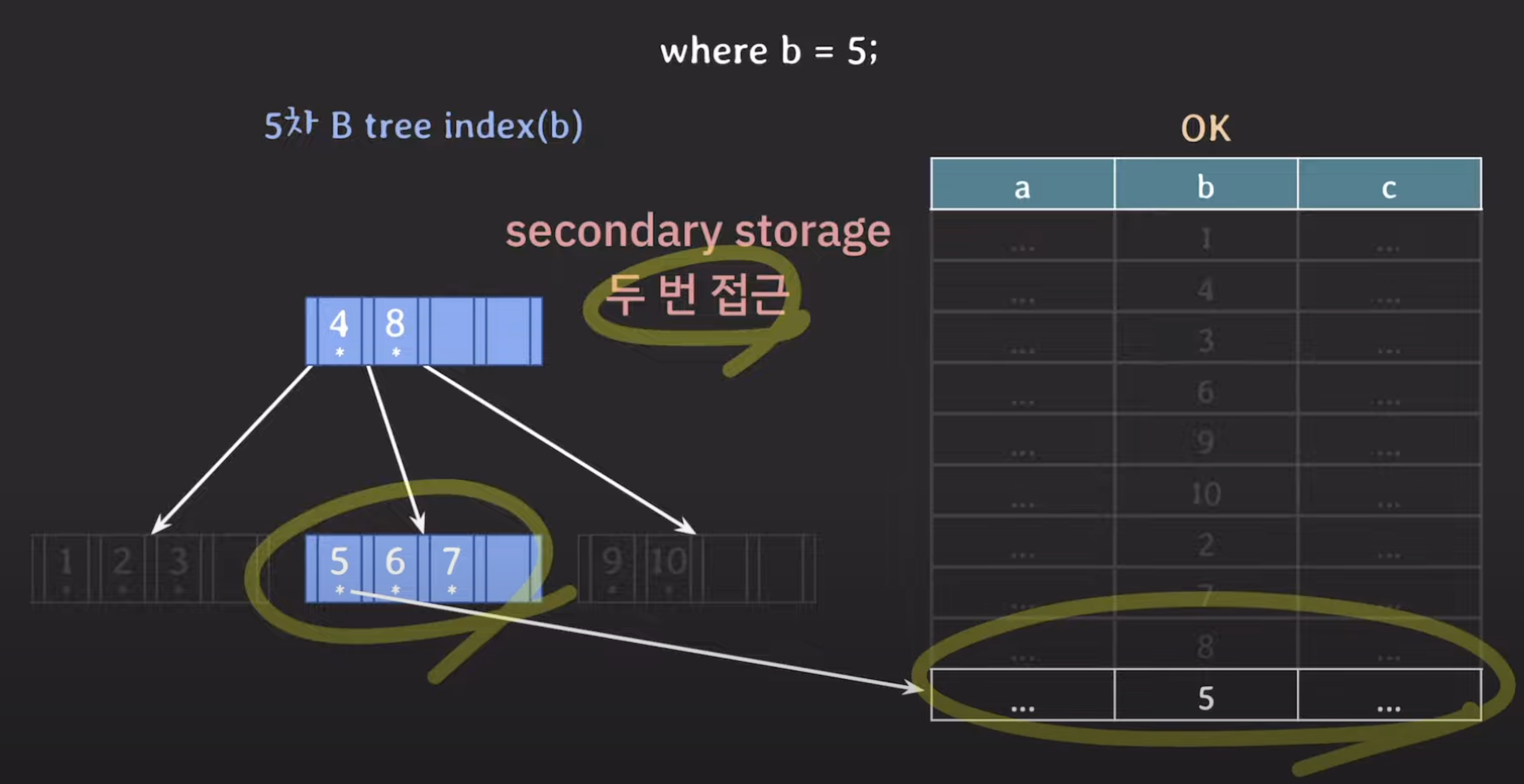
- 또한 5차 B tree의 경우 AVL tree의 자녀 노드 수가 1~2개인데에 비해 3~5개가 될 수 있기때문에 데이터를 찾을 때 탐색 범위를 빠르게 좁힐 수 있다.
- 그리고 5차 B tree의 경우 AVL tree의 노드의 데이터 수가 1개인데에 비해 2~4개가 될 수 있기때문에 block 단위에 대한 저장 공간 활용도가 더 좋다.
B tree의 강력함 - 101차 B tree가 best case일 때
- 조건
- 최대 자녀 수 : 101
- 최대 key 수 : 100
- 최소 자녀 수 : 51
- 최소 key 수 : 50
- 레벨 별 노드 수 - 데이터 수
- level 0 - 노드 수:1, 데이터 수:100
- level 1 - 노드 수:101, 데이터 수:101*100
- level 2 - 노드 수:101^2, 데이터 수:101^2 * 100
- level 3 - 노드 수:101^3, 데이터 수:101^3 * 100
- 깊이 3일때, 데이터 수는 약 1억개
worst case일 때
- 레벨 별 노드 수 - 데이터 수
- level 0 - 노드 수:1, 데이터 수:1
- level 1 - 노드 수:2, 데이터 수:2*50
- level 2 - 노드 수:2*51, 데이터 수:2*51*50
- level 3 - 노드 수:2*51^2, 데이터 수:2*51^2*50
- 깊이 3일때, 데이터 수는 약 26만개
- 즉, 4개의 level 만으로도 265301 < 전체 데이터 수 < 104060400 만큼의 데이터를 저장할 수 있다.
- 이는 곧 root 노드에서 가장 멀리 있는 데이터도 세 번의 이동만으로 접근할 수 있음을 말하고, 그 만큼 secondary storage에 적게 접근할 수 있다.
- 따라서 엄청난 양의 데이터를 저장하는 데이터베이스 사용에 적합한 자료구조인 것이다.
B tree 계열을 DB Index로 사용하는 이유 - 정리
- DB는 기본적으로 secondary storage에 저장된다.
- B tree index는 self-balancing BST에 비해 secondary storage 접근을 적게 한다.
- B tree 노드는 block 단위의 저장 공간을 알차게 사용할 수 있다.
hash index를 쓰는 것은?
hash index는 삽입/삭제/조회의 시간 복잡도가 O(1)이지만, = 조회만 가능하고, 범위 기반 검색이나 정렬에는 사용될 수 없다는 단점이 있다.
인용
https://www.youtube.com/watch?v=liPSnc6Wzfk&ab_channel=%EC%89%AC%EC%9A%B4%EC%BD%94%EB%93%9C
'컴퓨터 사이언스 > Database' 카테고리의 다른 글
| 트랜잭션의 격리 수준(Transaction Isolation Level) (0) | 2025.10.04 |
|---|---|
| DB Index (0) | 2023.08.24 |
| MongDB 사용법 (0) | 2023.08.08 |
| DB의 종류 (0) | 2023.08.08 |
| 데이터베이스 설계 실습 - 스타벅스 홈페이지 (0) | 2023.06.25 |
'컴퓨터 사이언스/Database' Related Articles
more
