
프로그램을 실행하고, 명령어 한 줄이 동작할 때마다 메모리와 CPU에서 일어나는 마이크로 연산을 명령어 사이클이라고 한다.
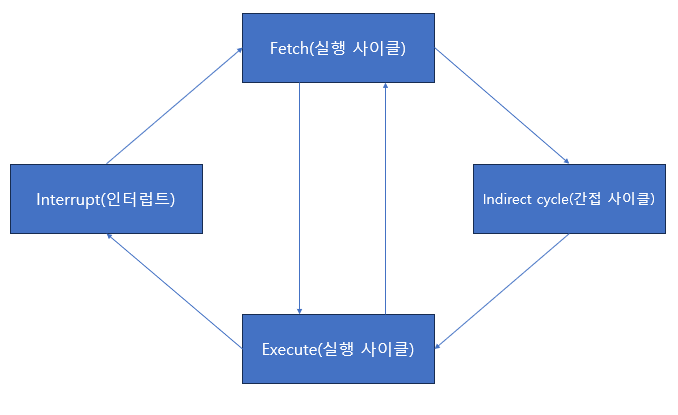
명령어 사이클의 순서는 다음과 같다.
인출 사이클 -> 간접 사이클 -> 실행 사이클 -> 인터럽트 사이클
- 인출 사이클 : 메모리에서 명령어를 CPU로 가져오는 단계
- 실행 사이클 : CPU에서 명령어를 실행하는 단계. 여기서 제어 장치는 명령어 레지스터에 담긴 값을 해석하고, 제어 신호를 발생시킨다.
- 간접 사이클 : 명령어를 실행하기 위해 한번 더 메모리 접근을 하는 과정을 간접 사이클이라고 한다. 간접 주소 지정 방식을 사용하는 경우에 필요한 사이클이다.
인출 사이클
인출 사이클은 현재 PC에 있는 주소의 내용을 가장 최근에 인출된 명령어가 저장되어 있는 레지스터인 IR 레지스터에 가져오게 한다. 자세한 마이크로 연산은 다음과 같다.
- PC안에 있는 주소를 PC에 저장된 명령어가 사용되기 전에 일시적으로 저장되는 주소 레지스터인 MAR로 보낸다. MAR은 기억장치에서 PC에서 받은 주소를 참조하여 해당 내용을 가져온다.
- 받은 내용은 기억장치에 저장될 데이터 혹은 읽혀진 데이터가 일시적으로 저장되는 버퍼 레지스터인 MBR을 통해 들어온다. 버퍼에 들어온 내용은 IR로 가져온다.
- 다음 명령어를 실행하기 위해 PC의 값을 1 증가시킨다.
이를 요약하면 다음과 같다.
- MAR <- PC
- MBR <- M[MAR], IR <- MBR
- PC <- PC + 1
간접 사이클
간접 사이클은 실행 사이클 전에 일어난다. 인출 사이클을 통해 IR에 가져온 명령어는 (명령어 + 주소)로 이루어져 있다. 그렇기 때문에 IR에 들어있는 피연산자를 참조해야 명령어가 인수로 가지는 데이터를 가져올 수 있게 된다. 따라서 해당 주소를 MAR로 가져와 기억장치의 해당 주소를 MBR을 거쳐 IR의 피연산자(operand) 부분에 넣어준다.
실행 사이클
실행 사이클은 IR에 있는 내용을 수행한다. 명령어를 수행하기 위해서 operand를 MAR로 보내어 기억장치에서 데이터를 가져온다. 그러면 데이터는 버퍼에 저장된다. 이 상태에서 이 상태에서 opcode 부분의 명령어 마다 각기 다른 마이크로연산에 차이가 발생한다.
- ADD : MBR에서 가져온 데이터와 AC에 있는 데이터를 더하고, 더한 값을 AC에 저장한다.
- LOAD : MBR에 있는 값을 AC에 덮어씌운다.
- STA : 이 명령어에서는 MBR에 먼저 저장이 안되어 있다. 그래서 먼저 IR에서 주소부분을 MAR로 가져와서 데이터를 저장할 위치를 기억한다. 그리고 AC에 있는 값을 버퍼에 가져와 제어버스를 거쳐서 기억장치에서 위에서 기억한 위치에 데이터를 덮어 씌운다.
- JUMP : IR에 있는 주소를 PC에 덮어 씌운다.
인터럽트 사이클
인터럽트 사이클은 실행 사이클이 끝난 후에 발생하는 사이클이다. 해당 사이클은 인터럽트 신호라는 것이 들어왔는지, 아닌지를 판단하는 사이클이다.
여기서 인터럽트란 CPU에게 긴급한 일을 알리는 방법인데, 명령어 사이클이 원활하게 진행되는 동안에 때때로 CPU는 인터럽트라는 메시지를 받는다. 그리고 이런 인터럽트는 크게 2가지로 나뉜다.
- 동기 인터럽트(예외) : CPU가 예기치 못한 상황에 부딪혔을 때 발생한다. 예를 들면, CPU가 접근해야 하는 주소에 접근했는데 메모리가 없거나, 연산 중에 오버플로우가 발생하는 경우가 있다. 이런 경우에 CPU는 현재의 작업을 중단하고 이러한 예외 상황을 처리한다.
- 비동기 인터럽트 : 비동기 인터럽트는 CPU가 다른 작업을 수행하는 도중에 외부에서 발생하는 이벤트에 의해 발생한다. 이들은 주로 입출력 장치(I/O devices), 타이머, 다른 프로세서에서 발생한다. 예를 들어, 키보드가 키 입력을 받았거나, 네트워크 카드가 데이터 패킷을 받았을 때, 이런 비동기 인터럽트가 발생할 수 있다. 이러한 인터럽트가 발생하면 CPU는 현재 작업을 일시 중단하거, 이 인터럽트를 처리한다.
그럼 이제 인터럽트 사이클에 대해 자세히 알아보자. 먼저 해당 사이클이 들어와있지 않다면 PC에 저장되어 있는 주소를 인출하는 인출 사이클을 시작으로 명령어의 사이클이 진행된다.
하지만 인터럽트 신호가 들어온 경우에는 인터럽트 사이클의 마이크로연산이 진행된다. 해당 사이클은 먼저 MBR에 현재 PC를 저장한다. 그리고 MAR에 SP(stack pointer)를 넣고, PC에 ISR 주소를 넣어준다. 그 이후에 MAR을 통해 SP의 주소로 MBR에 있는 기존 PC주소를 넣어준다. 그리고 SP의 값을 -1 해주어 다음 인터럽트 신호가 발생할 시에 PC 값을 넣을 위치로 설정해준다. 그리고 SP의 값을 -1 해주어 다음 인터럽트 신호가 발생할 시에 PC 값을 넣을 위치로 설정해준다.
다중 인터럽트 : 스택 구조를 이용하는 이유
인터럽트 사이클은 장치 X를 위한 ISR X를 처리하는 도중에 우선 순위가 더 높은 장치 Y로부터 인터럽트 요구가 들어와서 먼저 처리되는 경우가 생길 수 있다. 이를 다중 인터럽트라고 한다. 이러한 경우, 전에 취소된 명령어보다 기존 ISR이 우선이었기 때문에 해당 ISR이 먼저 실행되어야 한다. 이를 위해 LIFO 구조의 stack 자료구조가 필요하다.
기존 명령어 <- ISR X <- ISR Y
인용
https://velog.io/@onenewarm/%EB%AA%85%EB%A0%B9%EC%96%B4-%EC%82%AC%EC%9D%B4%ED%81%B4
명령어 사이클
명령어 사이클이란 프로그램을 실행 하고 명령어 한 줄이 동작 할 때, 메모리와 CPU에서 일어나는 마이크로 연산을 보여준다. 명령어 사이클의 순서는 다음과 같다.인출 사이클 → 간접 사이클
velog.io
https://taeyoungcoding.tistory.com/349
명령어 사이클과 인터럽트
( 명령어 사이클 [컴퓨터가 명령어를 처리하는 순서] ) 컴퓨터가 메모리에 있는 명령어를 실행하려면 먼저 CPU가 메모리에서 해당 명령어를 가져와야 한다. 이런 과정을 '인출'이라고 부른다. 그
taeyoungcoding.tistory.com
'컴퓨터 사이언스 > 컴퓨터 구조' 카테고리의 다른 글
| 레지스터의 역할과 종류 (0) | 2023.11.15 |
|---|---|
| Segmentation과 Paging의 개념 및 장단점 정리 (0) | 2023.11.14 |
| 주소 지정 방식 (0) | 2023.11.11 |
| 연산 코드와 오퍼랜드 (0) | 2023.11.11 |