
제네릭
다음의 ObjectBox 클래스는 어떤 오브젝든지 저장할 수 있고, 어떤 오브젝든지 꺼낼 수 있다. 하지만 꺼내서 사용할 때는 원래 타입으로 변환시키는 번거로운 과정이 필요하다.
ObjectBox box = new ObjectBox();
box.setObject("kim");
String str = (String) box.getObject();
System.out.println("str.toUpperCase() = " + str.toUpperCase());
box.setObject(5);
Integer i = (Integer) box.getObject();
System.out.println(i.intValue());이러한 과정을 해소시키위해 제네릭이라는 문법이 등장했다.
그리고 여기서 T는 아직 정해지지 않은 어떤 타입을 사용하겠다는 의미이다.
package theory.generics;
public class GenericBox<T> {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
}
package theory.generics;
public class GenericBoxMain {
public static void main(String[] args) {
GenericBox<String> box = new GenericBox<>();
box.setT("kim");
String str = box.getT();
System.out.println("str.toUpperCase() = " + str.toUpperCase());
}
}
위와 같이 <String> 으로 적어주면, 아직 정해져있지 않은 클래스 T를 String 타입으로 사용하겠다는 의미이다.
장점
정해진 타입만 사용하도록 강제할 수 있기때문에, 타입을 강제함으로써 컴파일할 때 잘못된 타입의 값이 저장되는 것을 막을 수 있다.
컬렉션 프레임워크
Java Collections Framework라고 불리워지는 Collections API는 자바2부터 추가된 자료구조 클래스 패키지이다. 즉, 자료를 다룰때 반드시 필요한 클래스의 모음이다.
다음 그림은 컬렉션 프레임워크의 핵심 인터페이스이다. 이때 Colletion 인터페이스는 자료를 순서없이 저장하고, Iterator 인터페이스를 의존한다. 자료구조에 대한 이해는 각 인터페이스에 대한 이해로부터 시작된다.
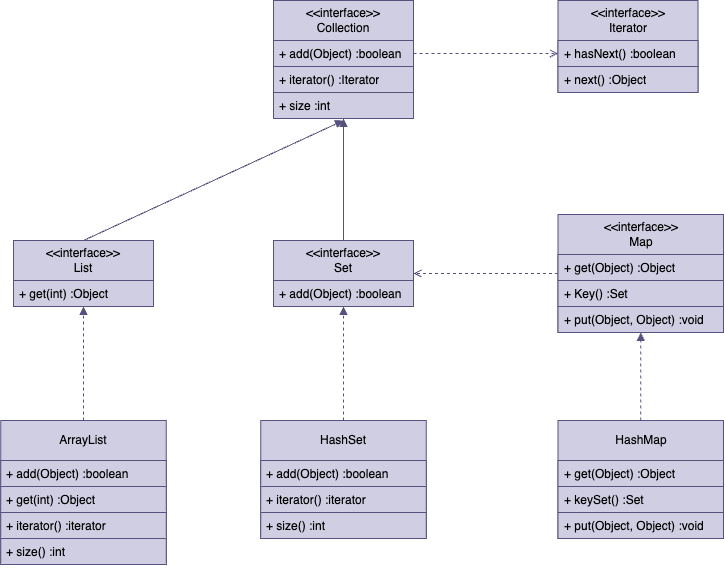
- Collection : 바구니. Collection은 모든 것을 꺼내기 위해서 Iterator에 의존한다.
- Iterator : 바구니에 있는 물건을 모두 꺼내고 싶을 때 사용. 즉, 자료구조에서 자료를 꺼내기 위한 목적으로 사용되는 인터페이스이다.
- 바구니에서 꺼낼 물건이 있는지 찾는다 : hasNext()
- 꺼낼 것이 있으면 하나 꺼낸다 : next()
- List : 객체를 저장하는데 그 순서를 기억하는 자료구조
- 순서를 알고있다고 가정하기 때문에 특정 순서로 저장된 자료를 꺼낼 수 있는 get(int) 메서드를 가지고 있다.
- Set : 중복을 허용하지 않는 자료구조. 같은 데이터는 1건만 저장.
- 같은 값을 여러번 추가하여도 마지막 값 하나만 저장됨을 의미한다.
- Set 인터페이스에 저장되는 객체들은 Object가 가지고있는 equals(), hashCode() 메서드를 Overriding해야한다.
- Map : key와 value로 구성된 자료구조
- key들만 모아놓게 되면 Set 자료구조가 된다. (중복X). 그리고 keySet() 메서드를 호출하게 되면 key들이 저장된 Set 이 반환된다.
- Iterator를 이용해서 key들을 꺼낼 수 있다.
ArrayList 사용하기
https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/ArrayList.html
ArrayList (Java SE 17 & JDK 17)
Type Parameters: E - the type of elements in this list All Implemented Interfaces: Serializable, Cloneable, Iterable , Collection , List , RandomAccess Direct Known Subclasses: AttributeList, RoleList, RoleUnresolvedList Resizable-array implementation of t
docs.oracle.com
자료구조 객체들을 제네릭을 사용하지 않으면 Object 타입을 저장한다. 따라서 꺼내서 사용할 때, 형변환이 필요하다.
다음 2개 코드의 차이를 생각해보자.
package theory.collection;
import java.util.ArrayList;
public class WithoutGenericArrayList {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("kim");
list.add("lee");
list.add("hong");
String str1 = (String) list.get(0);
String str2 = (String) list.get(1);
String str3 = (String) list.get(2);
System.out.println("str1 = " + str1);
System.out.println("str2 = " + str2);
System.out.println("str3 = " + str3);
}
}
package theory.collection;
import java.util.ArrayList;
public class WithGenericArrayList {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("kim");
list.add("lee");
list.add("hong");
String str1 = list.get(0);
String str2 = list.get(1);
String str3 = list.get(2);
System.out.println("str1 = " + str1);
System.out.println("str2 = " + str2);
System.out.println("str3 = " + str3);
}
}
Collection & Iterator
다음 코드는 참조 타입은 Collection이고, ArrayList 객체를 참조 변수 collection이 참조하고 있는 코드이다. 이게 가능한 이유는 ArrayList는 List Interface를 구현하고, List Interface는 Collection Interface를 상속하고 있기 때문이다.
이때 Iterator는 현재 collection에 포함된 자료를 꺼내기 위한 인터페이스이다.
package theory.collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class CollectionIter {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("kim");
collection.add("lee");
collection.add("hong");
System.out.println("collection.size() = " + collection.size());
Iterator<String> iter = collection.iterator();
while (iter.hasNext()) {
String str = iter.next();
System.out.println("str = " + str);
}
}
}
그리고 결과값이 순서대로 출력되는 것을 볼 수 있는데, 그 이유는 구현하고 있는 것이 ArrayList이고, iterator()를 ArrayList가 Override하고 구현했기 때문이다.
그리고 Collection을 구현하는 자료구조 객체는 엄청 많이 있다. 따라서 인스턴스로 사용하고자 하는 객체 타입이 무엇이 되든지 그 목적에 부합한 인터페이스 타입으로 참조해서 사용하는 것이 중요하다.
즉, 인터페이스 타입으로 참조 타입을 사용해서 프로그래밍하는 것이 중요하다. 아래 경우에는 ArrayList보다 더 나은 객체가 있으면 언제든 바꿔줄 수 있다는 장점이 있다.
package theory.collection;
import java.util.*;
public class CollectionIter {
public static void main(String[] args) {
List<String> collection = new ArrayList<>();
collection.add("kim");
collection.add("lee");
collection.add("hong");
System.out.println("collection.size() = " + collection.size());
Iterator<String> iter = collection.iterator();
while (iter.hasNext()) {
String str = iter.next();
System.out.println("str = " + str);
}
}
}
또한 인터페이스를 먼저 설계하는 훈련을 하는 것은 메서드 선언부터 하는 훈련이고, 결론적으로 자바 객체지향 프로그래밍이란 어떤 인터페이스가 있을까, 그 인터페이스들 간의 관계는 어떨까?하는 고민부터 시작해야 하는 것이다.
Set
Set 자료구조는 자료를 중복없이 저장할 수 있는 인터페이스이다.
Set<String> set = new HashSet<>();
boolean flag1 = set.add("kim");
boolean flag2 = set.add("lee");
boolean flag3 = set.add("hong");
boolean flag4 = set.add("hong");
System.out.println("flag3 = " + flag3);
System.out.println("flag4 = " + flag4);
Iterator<String> iter = set.iterator();
while (iter.hasNext()) {
String str = iter.next();
System.out.println("str = " + str);
}
Hash알고리즘 - hashCode(), equals() 동작 원리
다음 코드처럼 Set은 중복 허용이 되면 안되는 자료구조인데, 객체 타입을 만들어서 중복 자료를 저장하면 적용이 안되는 것을 볼 수 있다.
package theory.collection;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class SetMain2 {
public static void main(String[] args) {
Set<MyData> set = new HashSet<>();
set.add(new MyData("kim", 10));
set.add(new MyData("lee", 20));
set.add(new MyData("hong", 30));
set.add(new MyData("hong", 30));
Iterator<MyData> iter = set.iterator();
while (iter.hasNext()) {
MyData data = iter.next();
System.out.println("data = " + data);
}
}
}
class MyData {
private String name;
private int value;
public MyData(String name, int value) {
this.name = name;
this.value = value;
}
public String getName() {
return name;
}
public int getValue() {
return value;
}
@Override
public String toString() {
return "MyData{" +
"name='" + name + '\'' +
", value=" + value +
'}';
}
}
그래서 hashCode(), equals() 메서드가 등장한다.
HashSet은 Hash 알고리즘을 사용한다. HashSet에 A 자료를 저장하고자 하면, 자료를 저장하기 전에 이 자료가 가지고있는 hashCode()라는 메서드를 호출한다. 그리고 이 hashCode()가 '가'라는 값을 반환하면, '가'라고 이름이 붙어있는 바구니를 만든다. 그리고 이 바구니에 A자료를 넣어준다. 그리고 그 다음 자료 B가 들어오고, 만약 이 자료의 hashCode() 값이 '가'이면, '가'라는 바구니가 있으므로 저장할 때, 먼저 해당 바구니에 들어가있는 자료들이 중복되진 않는지 equals() 메서드로 비교해준다. 그리고 중복되지 않는다면 B를 '가' 바구니에 넣어준다.
즉, 두가지 메서드를 이용해서 Hash 알고리즘은 값을 저장하게 된다. 처음에는 hashCode()로 바구니를 생성하고, 그 바구니안의 값들은 순차적으로 equals()메서드를 이용해 값을 비교해 중복되지 않으면 값을 저장한다.
따라서 성능이 가장 빨라지려면 hashCode() 값이 다 달라야한다.
그리고 위의 코드에는 현재 hashCode(), equals() 가 없으므로, MyData를 HashSet에 넣어주는데 내부적으로 사용되는 hashCode(), equals()를 Object의 것으로 가져다쓰지만, Object에는 기준에 대한 제대로 된 기능이 구현되어 있지 않아 아무런 검사도 안해준다. 따라서 Hash 알고리즘을 사용하려면 이 메서드들을 Override 해주어야 한다.
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyData myData = (MyData) o;
return value == myData.value && Objects.equals(name, myData.name);
}
@Override
public int hashCode() {
return Objects.hash(name, value);
}이때 hashCode()는 유일한 값이 나오면 좋으므로 수학적 알고리즘이 사용된다.
Map
map의 key도 저장하기 위해 Hash 알고리즘을 사용하게 된다. 따라서 key의 타입은 equals, hashCode를 구현하고 있어야 하며, String의 경우에는 자체적으로 이미 해당 메서드를 오버라이딩하여 구현하고 있기 때문에 문제없이 사용이 가능하다.
그리고 Map의 경우 같이 key에 중복된 값이 저장되는 경우, 기존 값에 덮어씌워진다.
package theory.collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapMain {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("kim", "김");
map.put("lee", "이");
map.put("hong", "홍");
map.put("hong", "홍길동");
Set<String> keySet = map.keySet();
Iterator<String> iter = keySet.iterator();
while (iter.hasNext()) {
String key = iter.next();
String value = map.get(key);
System.out.println(key + ":" + value);
}
}
}
Collections 클래스
Collections.sort 즉 정렬을 할 수 있는데, Comparble 인터페이스를 구현하고 있는 객체만 정렬이 가능하다.
Collections.sort(collection);또한 Collections.shuffle(list);로 섞는다. 즉, Collections 라는 클래스는 다양한 자료구조에 대한 유틸리티를 가지고있다.
인용
'Language > Java' 카테고리의 다른 글
| I/O - File 클래스 (0) | 2023.09.18 |
|---|---|
| I/O (Input, Output) (0) | 2023.09.17 |
| 배열 (0) | 2023.09.16 |
| 익명 클래스 (Anonymous Class) (0) | 2023.09.15 |
| 팩토리 메서드 패턴과 Java Reflection (0) | 2023.09.15 |