
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- cross-cutting concerns
- ExceptionResolver
- #@Transacional
- Generic method
- generic type
- 벌크연산
- CQS
- Transaction
- CORS
- pessimistic lock
- API
- type eraser
- HandlerMethod
- RequestMappingHandlerMapping
- hoisting
- 역정규화
- SPOF
- assertJ
- 단어변환
- tracking-modes
- demand paging
- Java
- propagation
- COPYOFRANGE
- optimistic lock
- NestJS 요청흐름
- IllegalStateException
- 프로그래머스
- TDZ
- wrapper class
- Today
- Total
jingyulog
Set 본문
Collection Interface
Collection interface는 java.util package의 Collection Framework의 핵심 인터페이스 중 하나이다. 이 인터페이스는 자바에서 다양한 컬렉션. 즉, 데이터 그룹을 다루기 위한 메서드를 정의한다. 이 인터페이스는 List, Set, Queue와 같은 다양한 하위 인터페이스로 구현되며, 이를 통해 데이터를 List, Set, Queue 등의 형태로 관리할 수 있다.
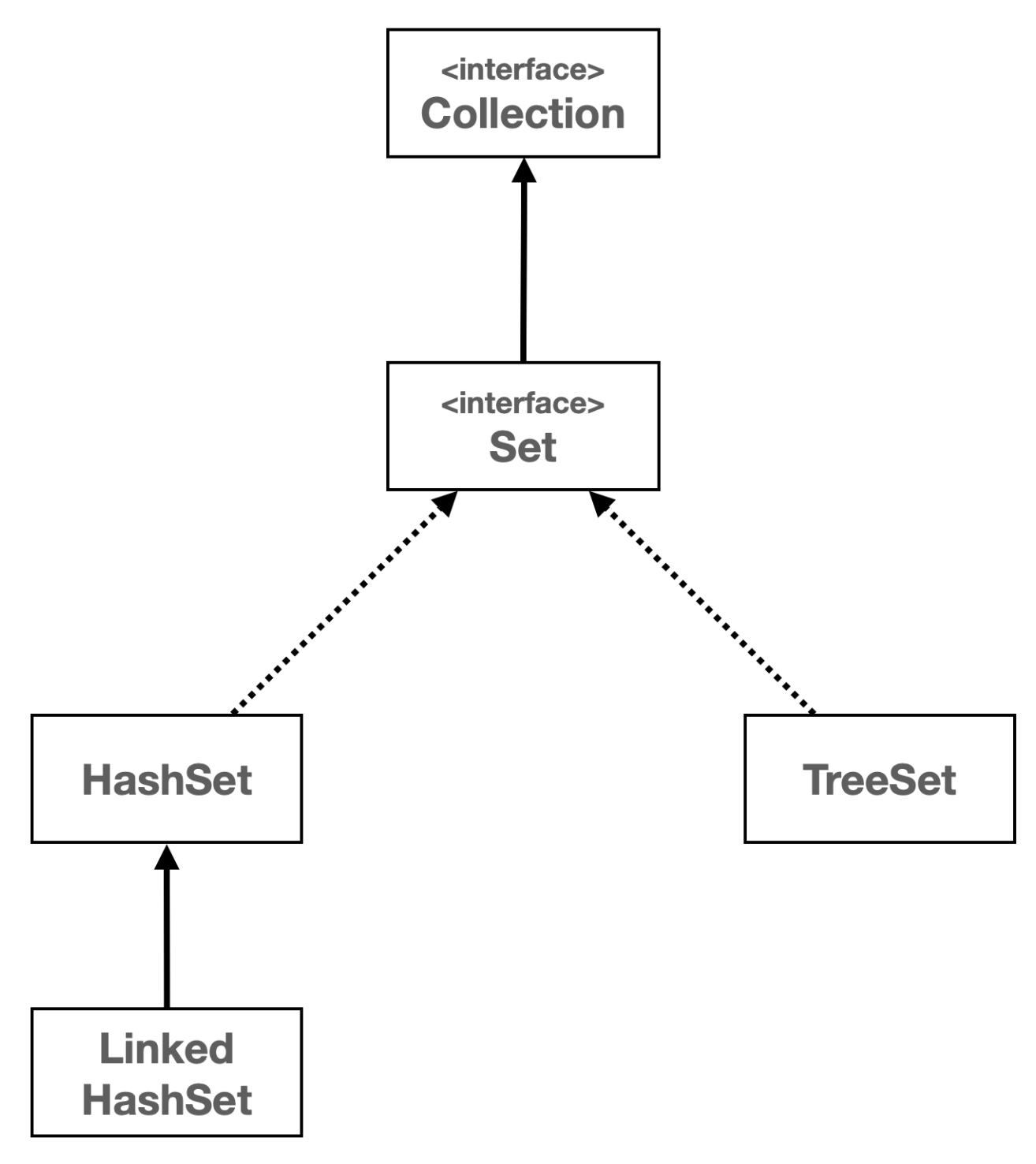
여기서 Set 인터페이스는 HashSet, LinkedHashSet, TreeSet 등의 여러 구현 클래스를 가지고 있으며, 각 클래스는 Set Interface를 구현하며 각각의 특성을 가지고 있다.
1. HashSet
해시 자료 구조를 사용해서 요소를 저장하며, 요소들은 특정한 순서 없이 저장된다. 즉, 요소를 추가한 순서를 보장하지 않는다. 따라서 데이터의 유일성만 중요하고, 순서가 중요하지 않은 경우에 적합하다.
추가, 삭제, 검색은 평균적으로 O(1)의 시간 복잡도를 가진다.
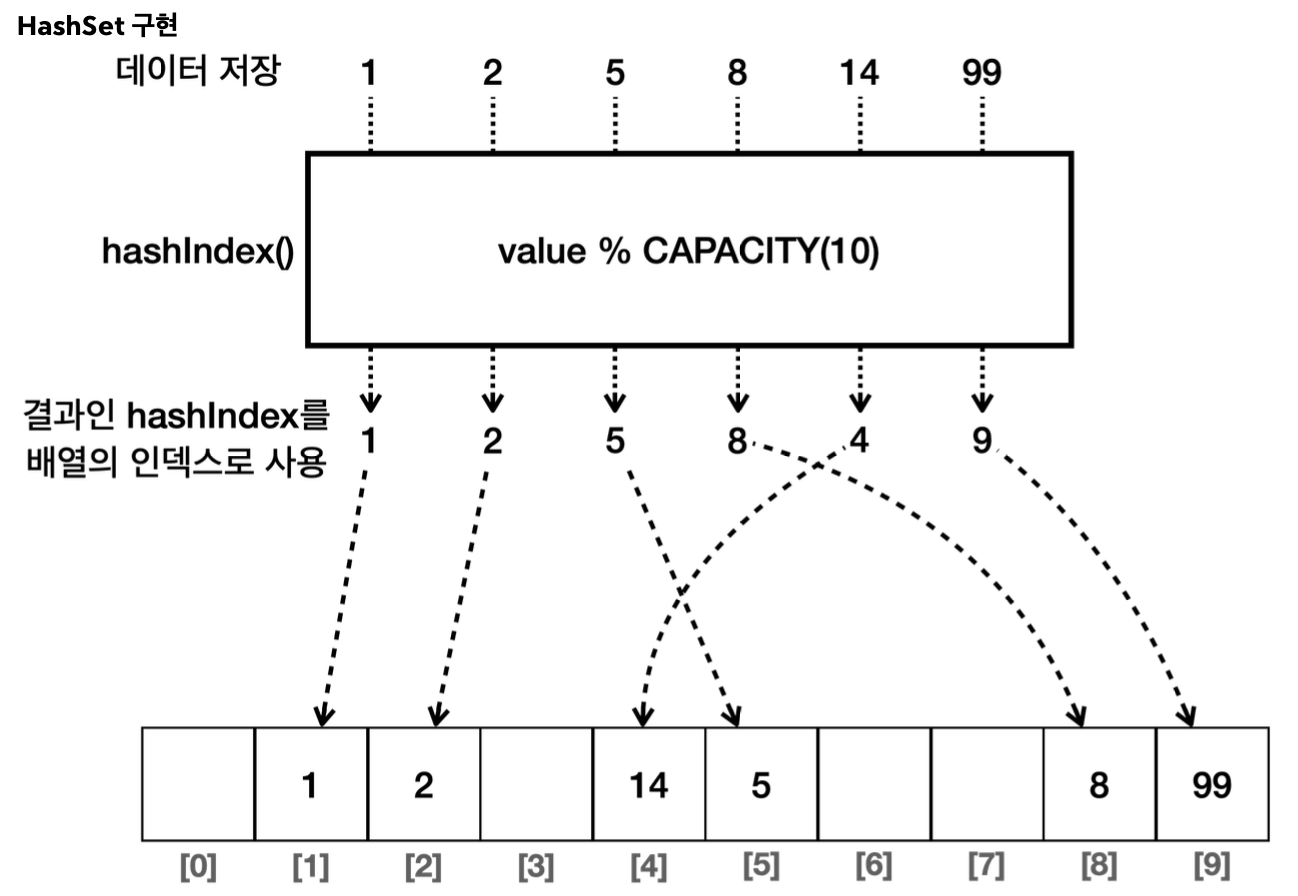
2. LinkedHashSet
LinkedHashSet은 HashSet에 연결 리스트를 추가해서 요소들의 순서를 유지한다. 이때, 요소들은 추가된 순서대로 유지되며, 조회시에도 요소들이 추가된 순서대로 반환된다. 따라서 데이터의 유일성과 함께 삽입 순서를 유지해야 할 때 적합하다. 다만 연결 링크를 유지해야 하기 때문에 HashSet보다는 조금 더 무겁다. 그래도 주요 연산에 시간 복잡도는 평균 O(1)을 유지한다.

- head(first) 부터 순서대로 링크를 따라가면 입력 순서대로 데이터를 순회할 수 있다. (양방향으로 연결된다.)
3. TreeSet
자바 TreeSet은 이진 탐색 트리를 개선한 레드-블랙 트리를 내부에서 사용한다. 덕분에 최악의 경우에도 O(log n)의 성능을 제공한다.S
요소들은 정렬된 순서대로 저장되며, 순서의 기준은 Comparator로 변경할 수 있다.
주요 연산들은 O(log n)의 시간 복잡도를 가지며, HashSet보다는 느리다.
따라서 데이터들을 정렬된 순서로 유지하면서 집합의 특성을 유지해야 할 때 사용한다. 예를 들어, 범위 검색이나 정렬된 데이터가 필요한 유용하다. 이때, 입력된 순서가 아니라 데이터 값이 순서라는 점을 유의해야 한다. 예를 들어, 3, 1, 2 순서대로 입력해도 1, 2, 3 순서로 출력된다.

java의 Set interface
java에서 제공하는 HashSet, LinkedHashSet, TreeSet 모두 Set interface를 구현하기 때문에 구현체를 변경하면서 실행할 수 있다.
- HashSet: 입력한 순서를 보장하지 않는다.
- LinkedHashSet: 입력한 순서를 정확히 보장한다.
- TreeSet: 데이터 값을 기준으로 정렬한다.
package src.set.javaset;
import java.util.*;
public class JavaSetMain {
public static void main(String[] args) {
run(new HashSet<>());
run(new LinkedHashSet<>());
run(new TreeSet<>());
}
}
private static void run(Set<String> set) {
System.out.println("set.getClass() = " + set.getClass());
set.add("C");
set.add("B");
set.add("A");
set.add("1");
set.add("2");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next() + " ");
}
System.out.println();
}
set.getClass() = class java.util.HashSet
A
1
B
2
C
set.getClass() = class java.util.LinkedHashSet
C
B
A
1
2
set.getClass() = class java.util.TreeSet
1
2
A
B
C이때, TreeSet을 사용할 때 데이터를 정렬하려면 크다, 작다라는 기준이 필요하다. 물론 1,2,3이나 A, B, C같은 기본 데이터는 크다, 작다라는 기준이 명확하기 때문에 정렬할 수 있다. 하지만 우리가 직접 만든 Member와 같은 객체는 Comparable, Comparator 인터페이스를 구현해야 한다.
최적화
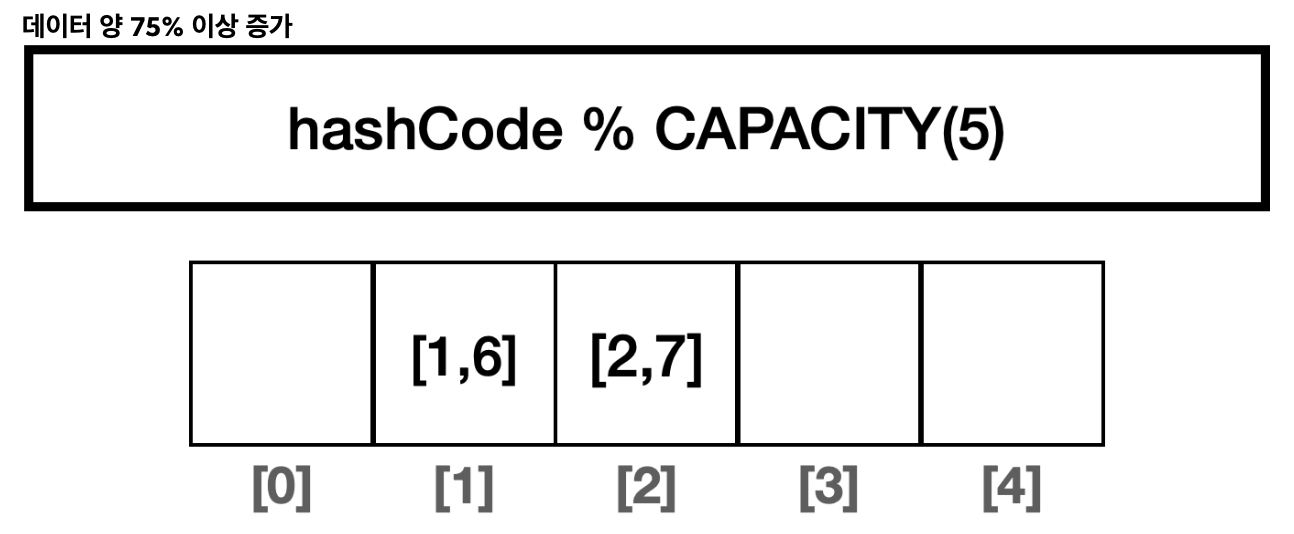
해시 기반 자료 구조를 사용하는 경우, 입력한 데이터의 수가 배열의 크기를 75% 정도 넘어가면 해시 인덱스가 자주 충돌한다. 따라서 75%가 넘어가면 해시 충돌로 같은 해시 인덱스에 들어간 데이터를 검색하려면 모두 탐색해야 하므로 성능이 O(n)으로 떨어지기 시작한다.
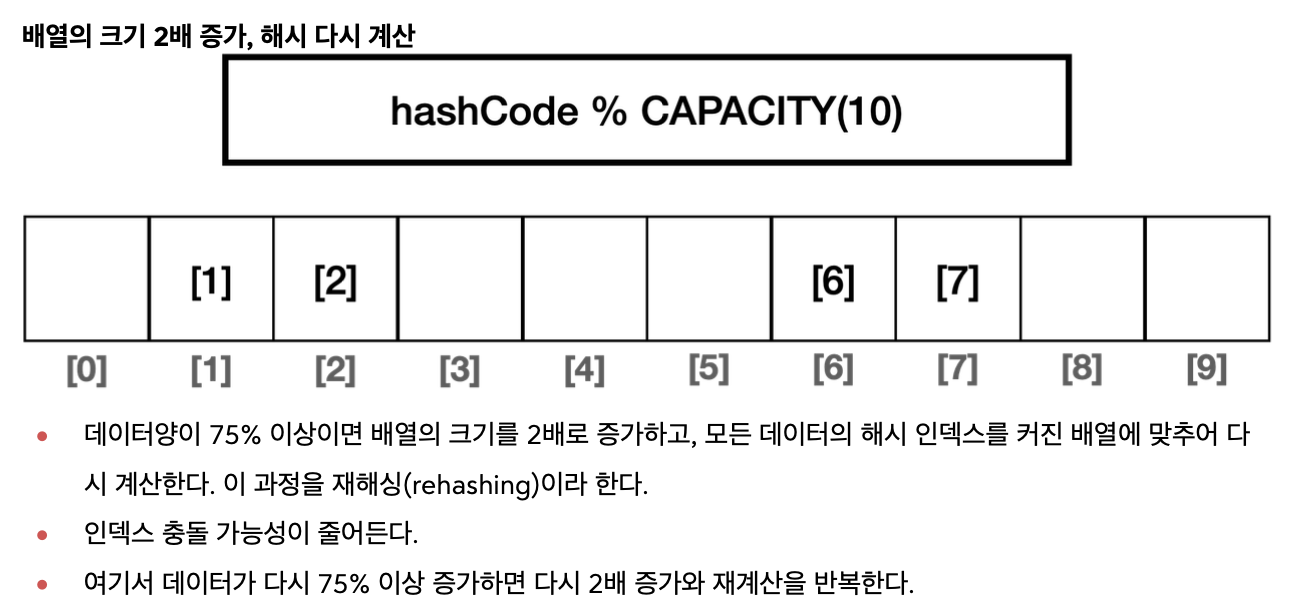
이에 자바의 HashSet은 데이터의 양이 배열 크기의 75%를 넘어가면 배열의 크기를 2배로 늘리고, 2배 늘어난 크기를 기준으로 모든 요소에 해시 인덱스를 다시 적용한다. 물론 이때 해시 인덱스를 다시 적용하는 시간이 걸리지만, 결과적으로는 해시 충돌이 줄어든다. 참고로 자바의 HashSet의 기본 크기는 16이다.
- 데이터 양이 75% 이상 증가하면 그 만큼 해시 인덱스의 충돌 가능성이 높아진다.
- 데이터 양이 75% 이상이면 배열의 크기를 2배로 증가하고, 모든 데이터의 해시 인덱스를 커진 배열에 맞추어 다시 계산하는데, 이 과정을 rehashing이라고 한다. 덕분에 인덱스 충돌 가능성이 줄어든다.
정리
정리하면 실무에서 Set이 필요한 경우에는 HashSet을 가장 많이 사용한다. 그리고 입력 순서 유지, 값 정렬의 필요에 따라서 LinkedHashSet, TreeSet을 선택하면 된다.
'컴퓨터 사이언스 > 자료구조' 카테고리의 다른 글
| 자바에서 Stack, Queue, Deque (0) | 2025.11.16 |
|---|---|
| Map (1) | 2025.11.08 |
| HashSet (0) | 2025.10.19 |
| Binary Search Tree, AVL Tree, Red-Black Tree (0) | 2025.10.11 |
| 이진 트리(Binary Tree) 소개 (0) | 2025.10.04 |