
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 벌크연산
- pessimistic lock
- SPOF
- tracking-modes
- hoisting
- COPYOFRANGE
- Transaction
- Generic method
- wrapper class
- type eraser
- 단어변환
- API
- #@Transacional
- 프로그래머스
- cross-cutting concerns
- NestJS 요청흐름
- 역정규화
- demand paging
- TDZ
- RequestMappingHandlerMapping
- optimistic lock
- propagation
- assertJ
- IllegalStateException
- CQS
- Java
- ExceptionResolver
- generic type
- CORS
- HandlerMethod
- Today
- Total
jingyulog
CSAPP - Procedures 본문
x86-64 스택
스택은 stack displine에 의해 관리되는 메모리 영역을 말한다. stack discipline이란 말그대로 스택을 관리하기 위한 일종의 규율과 같은 것이다. 스택은 %rsp 레지스터가 현재 스택의 가장 낮은 주소(top)을 저장하기로 되어있다. 또한 스택에 데이터가 쌓일 때는 낮은 주소 방향으로 쌓이도록 약속이 되어있다. 따라서 데이터를 push 할 때는 %rsp 의 값을 8만큼 감소시켜야 하고, 데이터를 pop할 때는 %rsp 의 값을 8만큼 증가시켜야 할 것이다.
x86-64 리눅스 스택 프레임은 Caller의 스택 프레임이 저장하는 데이터를 push하는 순서대로 나열하면 기존 %rbp, 백업된 레지스터들의 값, 지역 변수들. 즉, 자기 자신의 지역 데이터를 의미하는 값들과 호출할 함수의 인자들과 복귀 주소. 즉, 새로운 함수를 호출하려고 할 때 푸시되는 정보로 Callee의 인자와 복귀 주소를 저장한다.
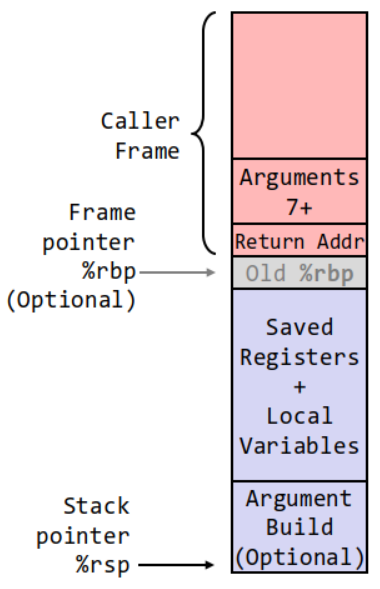
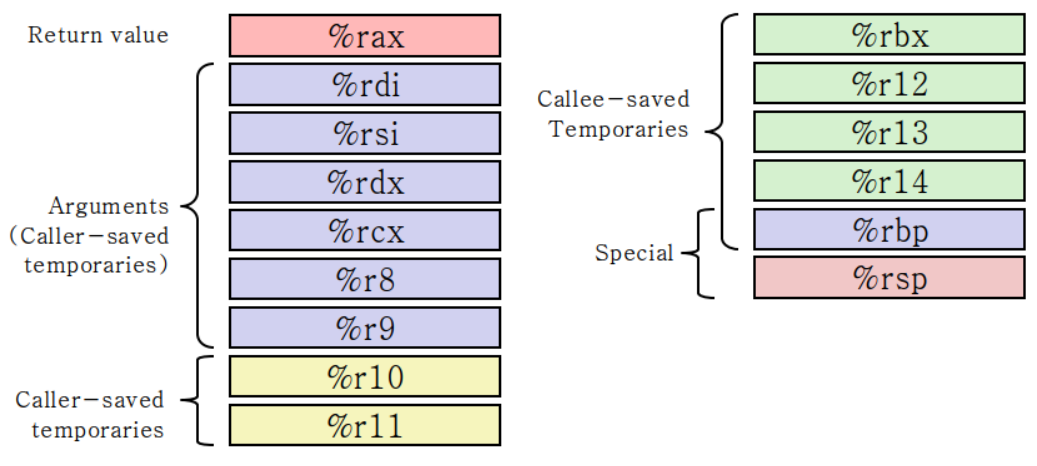
Caller-save 레지스터는 마음껏 건드려도 괜찮은 레지스터고, Callee-save 레지스터는 함부로 건드리면 안되는 레지스터이다.
C언어와 같은 스택 기반 언어는 재진입성(Reentrant)를 갖추고 있다. 즉, 한 프로시저에 대한 여러 개의 인스턴스가 만들어질 수 있으며, 각 인스턴스는 자신만의 지역 데이터를 관리하기 위한 스택 프레임을 가지고 있다. 또한 스택은 함수의 호출 및 return 패턴을 LIFO 구조로서 지원하고 있다. 즉, 재귀 함수를 구현하는 것은 별도의 작업이 전혀 필요하지 않다. 단순히 또 다른 함수를 호출하는 것과 같은 매커니즘으로 처리하면 된다.
Data
T A[L]; <- 자료형이 T인 데이터 L개로 이루어진 배열 A를 선언하는 문장이다. 배열의 할당은 어셈블리어 수준에서 메모리에 L x sizeof(T) 바이트를 연속적으로 할당함으로써 구현된다. 그리고 배열 요소의 접근은 어셈블리어 수준에서 배열의 첫 번째 요소를 가리키는 포인터인 A에 특정 인덱스 값을 더한 주소에 접근하는 방식으로 구현된다. A는 배열의 첫번째 요소를 가리키는 자료형이 T*인 포인터이다.

T A[R][C]; <- 자료형이 T인 데이터 R*C개로 이뤄진 2차원 배열 A를 선언하는 문장이다. 자료형 T인 데이터의 크기가 K라고 할 때, 2차원 배열의 총 크기는 R*C*K 바이트가 되는데, 실제 메모리 상에는 각 요소가 가로 방향으로 연속적으로 할당되어 있다. 이러한 할당 방식을 'Row Major Ordering'이라고 한다.

그렇다면 행 접근은 어떻게 나타낼까? A + i * ( C * K ) -> i번째 행에 해당하는 배열의 첫번째 요소를 가리키는 포인터를 나타내는 일반항이다. 즉, 만약에 4번째 행에 해당하는 배열의 첫번째 요소를 가리키는 포인터는 다음과 같이 A + i * (C* 4)로 나타낼 수 있고, 마지막 행은 A + ((R - 1) * C * 4)로 나타낼 수 있다. 즉, i가 찾고자하는 행의 번호이다.
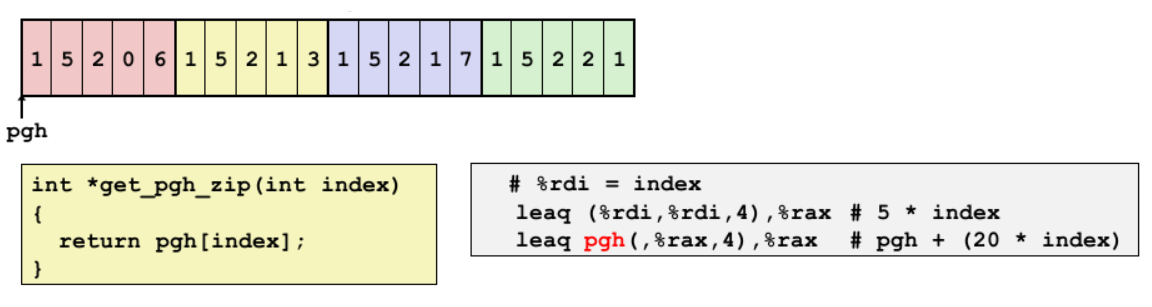
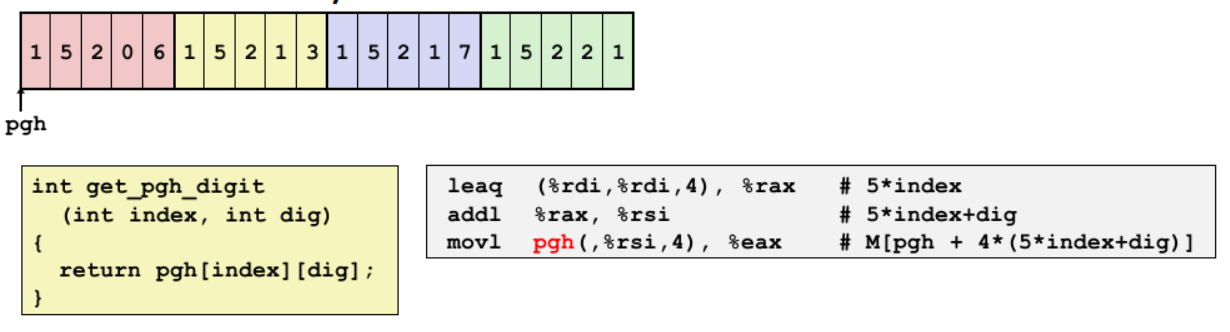
따라서 특정 A[i][j] 요소를 가리키는 포인터를 찾고자하면 다음과 같은 일반항 A + i * (C * K) + j * K 에서 도출하면 A + (i * C * 4) + (j * 4)처럼 찾을 수 있다. 즉, 다음과 같이 index 행의 dig 열을 찾고자 하면 다음과 같이 나타낼 수 있다.
반면에 Multi-level Array는 각 요소가 특정 배열을 가리키는 포인터인 배열을 의미한다. 이때, 다차원 배열과의 차이점은 크게 2가지인데, 첫 번째는 각 요소에 해당하는 배열들이 메모리 상에 순차적으로 할당된다는 보장이 없다는 것이다.

두 번째는 univ[i][j]에 접근할 때 메모리 접근이 2번 필요하다는 것이다. 즉, 먼저 univ[i]에 저장되어 있는 포인터를 읽고나서, 그 것에 인덱스 값을 더하여 얻은 주소로 다시 접근해서 값을 가져와야 하기 때문이다.

이렇게 다차원 배열과 멀티-레벨 배열은 근본적인 할당 구조가 다르기 때문에 요소에 접근하기 위한 기계어 코드도 달라질 수 밖에 없다.
그리고 위의 다차원 배열 내용을 기준으로 수학에서 다루는 N * N 정방 행렬을 구현하는 방법을 나열하면 크게 3가지로 나타낼 수 있다. 첫 번째는 고정 차원(Fixed Dimension), 두 번째는 가변 차원 및 명시적 인덱싱(Variable Dimension and Explicit Indexing), 세 번째는 가변 차원 및 암묵적 인덱싱(Variable Dimension and Implicit Indexing)이 있다. 고정 차원에서는 행렬의 가로 세로 길이에 해당하는 N을 컴파일 타임에 알고있는 경우로 C에 해당하는 N을 이미 알고있어서 컴파일러가 다음과 같이 올바르게 번역할 수 있다.

그 다음 가변 차원은 N을 컴파일 타임에 알 수 없는 행렬을 동적 배열로 구현하는 방식인데, 그 중 암묵적 인덱싱은 최근 gcc에 의해 채택되어 사용되는 현대적인 방식이다. 이 것은 인자로 전달받은 N의 값을 C 자리에 넣어주는 방식을 통해 컴파일러가 올바르게 번역할 수 있게 한다.

구조체도 배열과 마찬가지로 요소들이 메모리 공간에 연속적으로 할당되며 할당이 되는 순서는 구조체 내에서 선언되는 순서를 그대로 따른다. 컴파일러는 단지 해당 구조체의 전체 크기와 내부 요소들 각각의 위치 정보(offset)을 파악한 뒤 이를 바탕으로 구조체를 할당하고 접근하는 기계어 코드를 만들어 낸다.

구조체로 이루어진 연결 리스트가 있을 때는 각 구조체 내에 존재하는 배열 a와 정수 i에 대해 a[i]의 값을 val의 값으로 바꾸는 코드를 나타낸다.
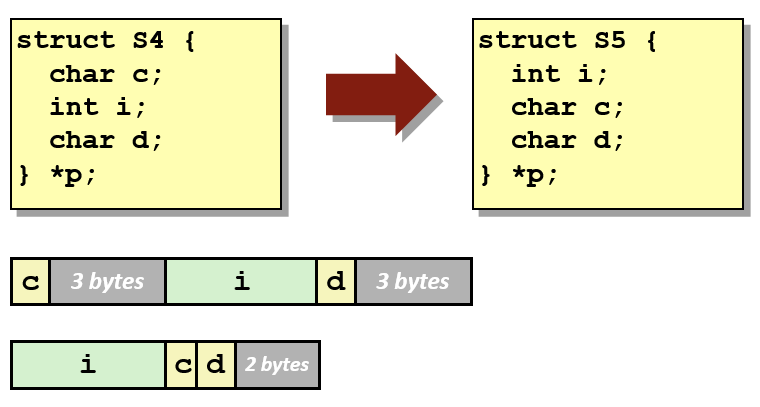
정렬 원칙(Alignment Principle). 사실 구조체 내 요소들은 완전히 연속적으로 할당되지는 않고 그 사이사이에 빈 공간이 존재하는데, 이는 성능 향상을 위한 정렬 원칙을 준수하기 위해서이다. 그리고 구조체의 정렬 원칙에 따르면 구조체 내 요소들을 크기가 큰 것부터 선언해야 공간을 가장 효율적으로 쓸 수 있다는 결론에 도달한다.

메모리 레이아웃이란 프로그램이 실행될 때 해당 프로그램의 데이터와 코드가 어느 곳에 어떻게 할당되는지를 나타내는 도식이다. 사실 엄밀하게는 프로그램의 데이터와 코드가 로드되는 가상 주소 공간의 구조를 나타낸다. 물론 이는 시스템마다 다른데 x86-64에서는 컴파일되는 프로그램을 실행하면 해당 프로그램의 데이터와 코드가 가상 주소 공간에 로드된다.

위 그림을 설명해보자면 다음과 같다.
- 스택 : 런타임 스택이라고도 하며, 8MB의 공간 제한이 있다. 지역 변수 등 함수 내 지역 데이터가 저장되는 영역이다.
- 힙 : 동적으로 할당되는 데이터들이 위치하는 영역이다. C 언어의 malloc(), calloc() 함수 등이 호출될 때 사용한다.
- 데이터 : 정적으로 할당되는 데이터들이 위치하는 영역이다. 전역 변수와 static 변수, 그리고 문자열 등의 상수가 이곳에 저장된다.
- 텍스트, 공유 라이브러리 : 프로그램 코드에 해당하는 명령어들이 순차적으로 저장되는 읽기 전용 영역이다. 프로그램 실행 파일의 코드는 텍스트 영역에, 공유 라이브러리 코드는 별도의 공간에 로드된다.

버퍼 오버플로우는 메모리에 할당된 공간을 의도와 다르게 접근하여 조작하는 대표적인 시스템 해킹 방법 중 하나이다. 다음 코드에서 배열 a는 길이가 2이므로 a[0], a[1]만 올바른 접근이라고 할 수 있다. 하지만 컴파일러는 a가 int형 데이터로 이루어진 배열의 첫 번째 요소를 가리키는 포인터라는 것만 알고, 그 배열의 길이는 따로 기억하지 않는다. 따라서 a[2], a[3]도 정상적으로 컴파일이 되고, 실행으로까지 이루어진다. 이 경우에 3.14에 해당하는 값을 d 자리에 올바르게 저장했는데도 불구하고 배열 a에 대한 잘못된 접근으로 인해 d 자리에 잘못된 값이 쓰여진다. 이처럼 허용된 공간을 초과하여 메모리에 접근함으로써 메모리를 조작하는 것이 버퍼 오버플로우의 대표적인 사례이다.

이러한 버퍼 오버플로우 공격의 대표적인 사례가 바로 Code Injection 이다. 즉, 호출한 함수로의 복귀 주소를 해커가 의도한 코드로 리턴함으로써 잘못된 코드가 실행되는 것이다.
C언어의 Union은 구조체와 많이 비교되는 자료구조이다. 구조체는 멤버 변수들이 메모리 상에 선언된 순서대로 할당이 되지만, 공용체는 하나의 공간을 여러 변수가 공유하여 사용한다.
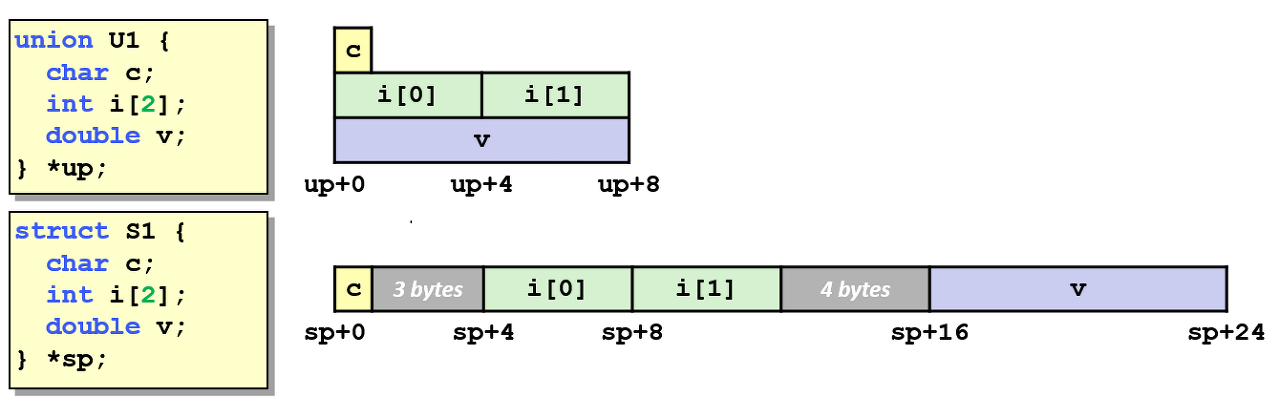
공용체의 가장 큰 장점은 하나의 공간을 여러 자료형의 관점에서 사용할 수 있다는 것이다.
다음에서는 매개변수로 전달되는 정수 값을 공용체에 저장한 뒤 그 값을 float 형으로 반환한다.즉, 비트상에는 u에 해당하는 정수 값이 2의 보수로 표현되어 있지만, 그 비트 배열은 그대로 둔 채 해석만 float 방식으로 하겠다는 의미이다.

바이트 오더링이란 메모리에 연속적으로 할당되는 데이터들의 비트 배열 방향을 나타낸다. 주소가 가장 작은 부분이 MSB이면 Big Endian 방식, 주소가 가장 큰 부분이 MSB이면 Little Endian 방식이라고 한다. x86-64의 경우에는 Little Endian 방식을 채택하고 있다.

인용
https://it-eldorado.tistory.com/39
[CSAPP] x86-64 - Miscellaneous Topics
1. 메모리 레이아웃 1-1. x86-64 메모리 레이아웃 (Memory Layout) 메모리 레이아웃(Memory Layout)이란 프로그램이 실행될 때 해당 프로그램의 데이터와 코드가 어느 곳에 어떻게 할당되는지를 나타내는 도
it-eldorado.tistory.com
'책 - 요약 정리 > CSAPP' 카테고리의 다른 글
| Network Programming (0) | 2023.11.17 |
|---|---|
| Virtual Memory (0) | 2023.11.08 |
| Exceptional Control Flow (0) | 2023.11.07 |
| linking (0) | 2023.11.07 |



